개요
SAP HANA에 대한 기본적인 개념을 정리해보고자 한다. SAP HANA 개요와 기술적 발전, HANA 플랫폼, 컬럼 로우 저장 방식의 차이, 파티셔닝 및 Insert Only Delta에 대해서 알아보고 정리해볼 예정이다.
SAP HANA 개요
SAP HANA는 인메모리 기술을 활용하여 디스크가 아닌 메인 메모리에서 데이터를 직접처리한다. 메인 메모리에서 처리하기에 속도가 빠르고 대용량 데이터 분석 성능이 뛰어나다.
기존의 3계층 아키텍처를 개선하여 데이터와 애플리케이션 계층을 통합하였다. 기존의 아키텍처는 데이터, 애플리케이션, 프레젠테이션 계층으로 나뉘어서 데이터를 저장하는 계층과 계산하는 계층이 분리되어 있었다. 데이터와 애플리케이션 계층을 통합하여 데이터를 이동시키는 것이 아니라 연산을 데이터가 있는 곳에서 수행하는 방식을 인메모리 컴퓨팅 기술을 도입하며 적용시켰다. 이는 현대 비즈니스 환경에서 요구되는 센서 데이터, 소셜 네트워크 데이터, 실시간 분석 요구 데이터와 같은 빅데이터 분석에 효율적이다.
SAP HANA의 기술적 발전
컴퓨팅 기술의 발전(1990~2016)
| 항목 | 1990 | 2010 | 2016 개선율 |
| CPU 성능 (MIPS/$) | 0.05 | 7.15 | 143배 증가 |
| 메모리 용량 (MB/$) | 0.02 | 5 | 250배 증가 |
| 주소 지정 가능 메모리 (비트 크기) | 2^16 | 2^64 | 2^48배 증가 |
| 네트워크 속도 | 100 Mbps | 10 Gbps | 100배 증가 |
| 디스크 데이터 전송 속도 | 5 MBPS | 130 MBPS | 25배 증가 |

현대 컴퓨터 아키텍처의 변화
1. 64비트 프로세서 설계
- 64비트 프로세서는 한 사이클 동안 64비트(8바이트)를 동시에 처리 가능
- 데이터 및 어드레스 버스, 레지스터 세트의 폭이 64비트로 설계되며 명령어 세트도 일반적으로 64비트로 기반으로 구성됨
- 단 x86 아키텍처와 같은 레거시 호환성을 유지하는 경우도 존재
2. 데이터 처리 가속화 기술
- 하드 디스크의 바깥쪽 트렉에서의 쓰기 작업 감소, 하드 드라이브 자체의 데이터 전처리, 대형 캐시 활용 등 다양한 가속화 기술이 개발됨
- 기존의 기술들은 기본적으로 데이터를 하드 드라이브에 저장하고 접근 속도를 높이는 방식
- 대용량 메모리가 저렴해지고 64비트 운영체제를 사용함으로써 하드 드라이브를 대체하여 메인 메모리를 활용하는 방안이 떠오름
3. 멀티코어 프로세서의 발전
- 32비트 주소 공간은 4GB 메모리로 제한되지만 64비트 어드레스 스페이스는 서버가 감당할 수 없을 정도로 방대한 메모리를 활용 가능
- 메인 메모리에 있는 데이터가 유용하려면 CPU가 이를 충분히 처리할 수 있어야 함
- 단일 CPU에서 다중 코어 프로세서 구조로 전환되며 CPU 처리 능력이 향상
4. 현대 컴퓨터 아키텍처의 변화 정리
- 멀티코어 CPU가 표준이 되었으며 프로세서 코어 간의 초고속 통신을 통해 병렬 처리가 가능
- 메인 메모리는 더 이상 제한된 자원이 아니며 최신 서버는 수 테라바이트 이상의 시스템 메모리를 탑재하여 전체 데이터베이스를 RAM에 저장할 수 있음
- 현재 서버용 프로세서는 최대 64코어를 지원하며 곧 128코어 프로세서도 출시
- 코어 수 증가로 인해 CPU는 단위 시간당 더 많은 데이터를 처리할 수 있으며 이에 따라 성능 병목 현상이 디스크 I/O에서 CPU 캐시와 메인 메모리 간 데이터 전송으로 이동
5. SAP HANA와 병렬 처리 최적화
- SAP HANA는 전체 작업을 다수의 작은 스레드로 분할하여 다중 코어를 최대한 활용할 수 있도록 설계됨
- 최적의 데이터 구조 설계가 필수적이며 컬럼 기반 방식을 사용하여 여러 쿼가 동시에 개별 컬럼을 처리할 수 있음
- 이를 통해 병렬 처리 방식 효율이 극대화
HANA 플랫폼
SAP HANA는 단순한 데이터베이스가 아니라 다양한 기능을 포함한 플랫폼이다. SAP HANA의 구성요소는 다음과 같다.
- 애플리케이션 개발 : 내장된 애플리케이션 서버를 통해 다양한 언어를 지원하는 네이티브 SAP HANA 애플리케이션을 개발할 수 있다.
- 고급 분석 처리 : 텍스트 분석, 예측 분석, 공간 분석, 그래프 분석, 스트리밍 데이터 및 시계열 데이터를 처리할 수 있는 강력한 데이터 처리 엔진을 제공한다.
- 데이터 통합 및 품질 관리 : 실시간 및 배치 ETL 도구를 제공하여 다양한 소스의 데이터를 통합하고 품질을 유지할 수 있따.
- 데이터베이스 관리 : 인메모리 데이터베이스 및 고급 데이터 관리 도구를 포함한다.
컬럼, 로우 스토어
컬럼 스토어와 로우 스토어
- SAP는 두 가지 테이블 저장 방식 ( 컬럼 스토어와 로우 스토어 ) 을 지원
- 컬럼 스토어: 같은 컬럼의 데이터를 연속적인 메모리 공간에 저장
- 로우 스토어: 하나의 행에 포함된 모든 필드를 연속적으로 저장
- SAP HANA는 컬럼 스토리지에 최적화되어 있으며 필요에 따라 테이블 저장 방식을 변경할 수도 있음
컬럼 스토어의 성능 이점
1. CPU 캐시 활용과 성능 최적화
- 로우 스토어 : 한번의 CPU 캐시 로드에 필요한 데이터 외에도 여러 필드가 포함되므로 캐시 미스가 발생할 확률이 높음
- 컬럼 스토어 : 필요한 컬럼 데이터만 연속적인 메모리 공간에 저장되어 CPU 캐시 활용이 최적화 됨.
2. 데이터 압축 최적화
- 컬럼 스토어에서는 데이터 압축을 활용하여 메모리 사용량을 줄이고 성능을 향상시킴
- SAP HANA는 기본적으로 Dictionary 압축을 적용하여 중복된 값을 숫자로 매핑하여 저장
- 추가적으로 고급 압축 기법 적용 가능
- Prefix Encoding : 같은 접두어를 묶어 압축
- Run-Length Encoding(RLE): 연속된 동일 값을 하나로 저장
- Cluster Encoding: 비슷한 값을 그룹화
- Sparse ENcoding, Indirect Encoding: 특수한 패털을 활용하여 압축
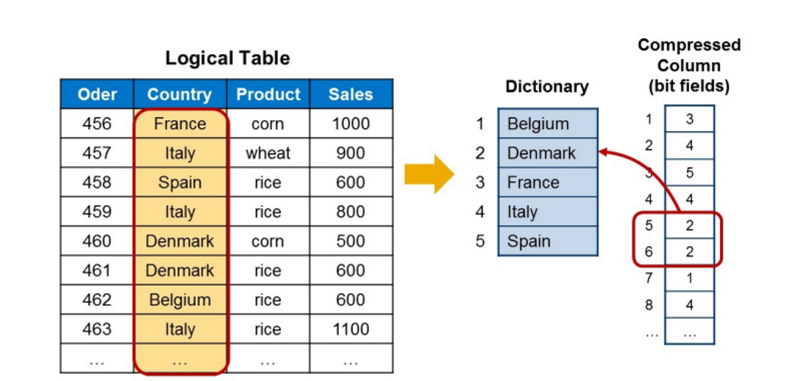
3. 고급 분석을 위한 최적화
- 컬럼스토어를 사용할 시 고속 분석을 위한 최적화 기능 제공
- 고성능 압축: 동일한 값이 연속적으로 저장되므로 압축 효율이 높음
- 컬럼 연산 성능 향상: 특정 컬럼을 대상으로 한 검색, 필터링, 집계 성능이 뛰어남
- 추가 인덱스 불필요: 컬럼 단위로 저장되므로 별도의 인덱스 없이도 검색 속도가 빠름
- 미리 저장된 집계 데이터 불필요: 기존 데이터웨어하우스에서는 미리 계산된 집계 데이터 (materialized aggregates)를 저장했으나 SAP HANA는 컬럼 스토어를 활용해 실시간으로 집계 계산 가능
- 병렬 처리 최적화: 컬럼 데이터가 독립적으로 저장되므로 여러 CPU가 동시에 병렬 처리할 수 있음
로우 스토어와 컬럼 스토어 선택 기준
| 저장 방식 | 적합한 사용 사례 |
| 로우 스토어 (Row Store) | 전체 행을 자주 조회해야 하는 경우 (OLTP 시스템) |
| 컬럼 스토어 (Column Store) | 대량 데이터를 분석하고 집계해야 하는 경우 (OLAP 시스템, 데이터 웨어하우스) |
- 로우 스토어: 모든 컬럼을 한 번에 읽어야 하는 경우 유리(트랜잭션 처리)
- 컬럼 스토어: 특정 컬러만 필요한 경우 성능 최적화 가능(분석 및 보고)
SAP HANA에서 컬럼 스토어 적용 방식
SAP 시스템이 HANA로 마이그레잇ㄴ 될 때 자동으로 최적의 방식 선택
대부분의 테이블은 컬럼 스토어
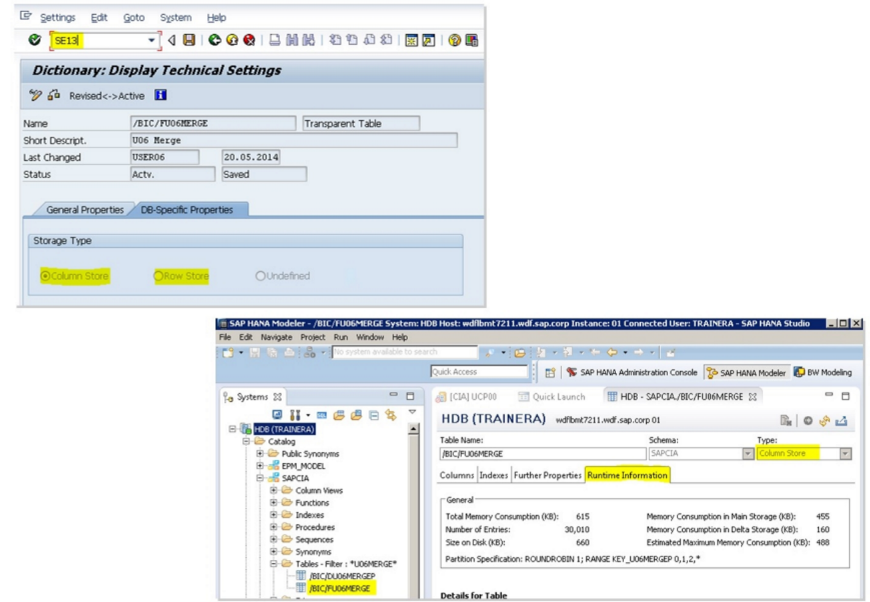
HANA Studio, T-CODE: SE13에서 확인 가능
파티셔닝 및 Insert Only On Delta
데이터 파티셔닝과 병렬 처리
파티셔닝 개념
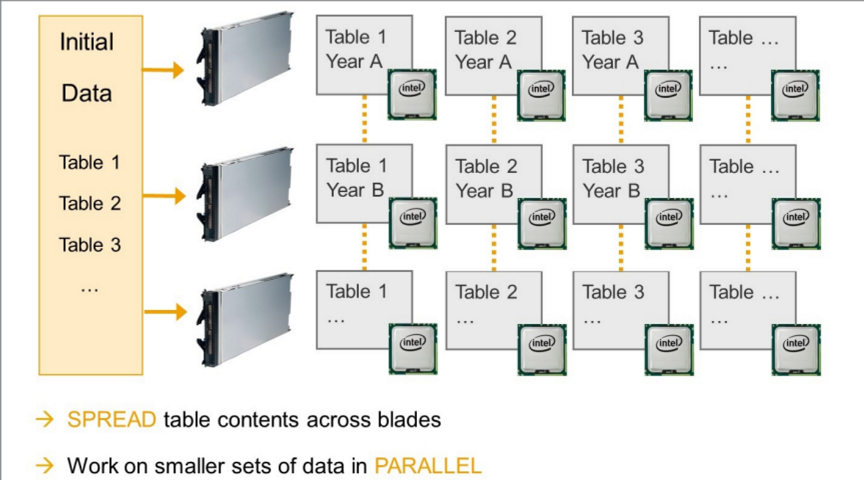
- 대량의 데이터를 빠르게 처리하기 위해 데이터를 여러 개의 작은 파티션으로 나누어 저장
- 각 파티션은 독립적인 단위로 병렬 처리 가능
- 예를 들어 1억 개의 데이터가 있다면 이를 10개의 파티션으로 나누어 10개의 CPU 코어에서 병렬로 처리 가능
파티셔닝 장점
- 병렬 처리 지원 - 여러 CPU 동시 처리
- 쿼리 성능 향상 - 전체가 아닌 특정 파티션만 조회 가능
- 데이터 로드 및 관리 최적화 - 파티션 단위로 로드 및 관리 가능
SAP HANA의 Insert Only on Delta(델타 저장 방식)
1. 컬럼 스토어에서의 데이터 삽입 및 수정 문제
- 컬럼 스토어는 데이터를 압축 저장. 데이터는 정렬된 상태 유지.
- 새로운 데이터 삽입 시 기존 데이터가 변경 시 정렬을 재수행해야 하기에 잦은 변경에 따른 성능 저하 발생
- 쓰기 연산(Insert/UPDATE)에는 비효율적
2. 델타 저장소
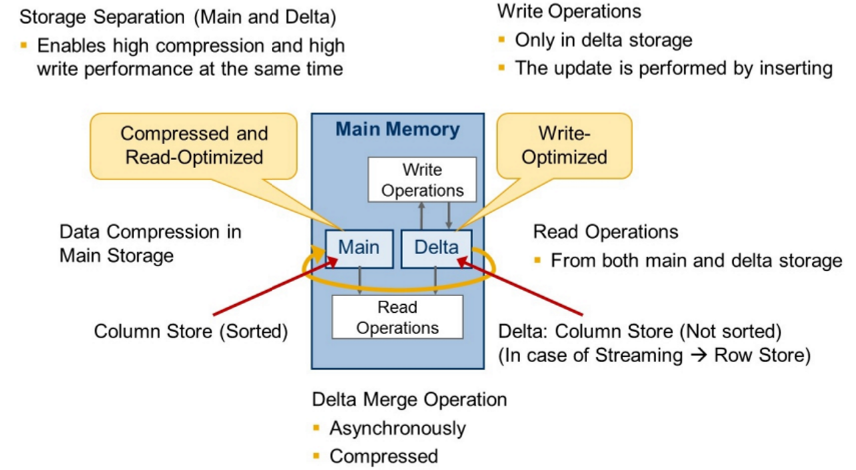
SAP HANA는 쓰기 연산을 최적화 하기 위해 데이터를 메인/델타 두 개의 저장소로 분리
- 메인 스토리지
- 읽기 성능에 최적화
- 정렬된 컬럼 데이터로 저장
- 데이터 분석 및 조회 시 사용
- 델타 스토리지
- 쓰기 성능에 최적화
- 정렬되지 않은 데이터가 저장
- 새로운 삽인 또는 변경 데이터가 저장
- 메모리 내에만 존재, Persistence Layer에는 델타로그만 기록
3. Delta Merge 프로세스
- 델타 스토리지에 쌓인 데이터가 많아지면 SAP HANA는 주기적으로 델타 데이터를 메인 스토리지로 병합하는 작업 수행
- 이 과정을 Delta Merge라고 함
- Delta Merge는 쿼리 성능을 유지하면서도 삽입/수정 성능을 최적화하는 중요 기법
결론 및 정리
SAP HANA의 기본적인 내용과 기술 발전에 따른 변화를 알아보았고 컬럼 저장 방식, 데이터 압축, 파티셔닝 및 델타 저장 방식에 대해서 알아보았다. SAP의 근본이 되는 기술이 되어가는 HANA DB의 가장 핵심이 되는 기술들만 골라서 알아보았으며 이를 머리속에 새겨두고 데이터를 다룰 필요가 있으리라고 생각했다.
'BW' 카테고리의 다른 글
| aDSO 및 모델링 활용 이것저것 (0) | 2025.03.27 |
|---|---|
| LSA++ 아키텍처 (0) | 2025.03.10 |
| SAP Certi C_BW4H 합격 후기 (0) | 2025.03.02 |
| SAP 러닝허브 구독 후 (0) | 2025.02.19 |
| BW - 개념정리 (1) | 2024.12.09 |